-
Jun 2026
New journey begins at Runway as Member of Technical Staff.
-
Oct 11, 2021
New journey begins in Snap Research.
-
May 20, 2019
Onboarding day for IBM Research.
-
Apr 19, 2019
Sussessfully defensed my Ph.D dissertation!
-
Feb 3, 2019
One paper is accepted to IEEE ICC'19.
-
Jan 7, 2019
Our BatMapper extended journal version is accpeted to IEEE Transactions on Mobile Computing (TMC).
-
Oct 31, 2018
I presented at MobiCom'18, New Delhi, India.
-
Aug 13, 2018
I presented my work "Active Visual Recognition in Augmented Reality" at IBM Research.
-
Jul 20, 2018
Our paper EchoPrint is accepted to MobiCom'18, congrats to all co-authors!
-
Jul 2, 2018
Our Knitter journal paper is accepted to IEEE Transactions on Mobile Computing (TMC).
-
May 24, 2018
I started my summer internship at IBM Thomas J. Watson Research Center, Yorktown, NY.
-
Apr 5, 2018
My EasyFind project won First Prize at Entrepreneur Challenge 2018 at Stony Brook University with $10,000 cash awards for turning this cool project into product.
-
Feb 16-18, 2018
My augmented reality project EasyFind won the Finalist Prize at Hackathon@CEWIT'18 (Top 6 teams).
-
Nov 5-8, 2017
I presented our work BatTracker at SenSys'17, Delft, The Netherlands. Unforgettable banquet!
-
Oct 16-20, 2017
I presented our BatMapper demo at MobiCom'17, Snowbird, Utah, USA.
-
Jul 17, 2017
Our paper on infrastructure-free mobile device tracking, BatTracker, is accepted to SenSys'17.
-
Jun 19-23, 2017
I presented our work BatMapper at MobiSys'17, Niagara Falls, NY, USA. Breathtaking scenery!
-
May 1-4, 2017
I'm attending IEEE INFOCOM'17 at Atlanta, GA, USA.
-
Mar 1, 2017
Our acoustic based indoor mapping paper, BatMapper, is accepted to MobiSys'17.
-
Feb 23, 2017
Our acoustic based indoor mapping project is awarded a Google Research Award. Thanks Google!
-
Feb 17-19, 2017
Our wearable project Billiards Guru won the Finalist Prize at Hackathon@CEWIT'17 (Top 6 teams).
-
Jan 27, 2017
A paper is accepted to IEEE ICC'17.
-
Nov 25, 2016
Our paper on indoor mapping, Knitter, is accepted to INFOCOM'17.
![[Bing Zhou]](images/bingsnap.jpg)











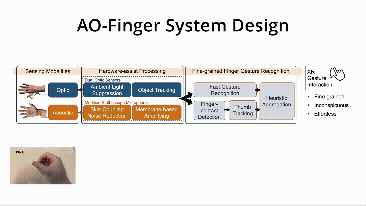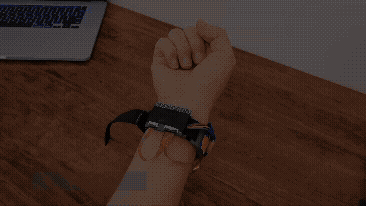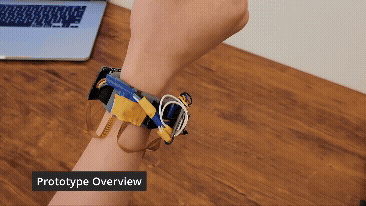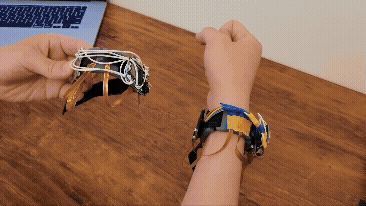
![[CCM]](images/knitter.png)



